__global__ voidmatrixMultiplyKernel(float *A, float *B, float *C, int m, int n, int k){ // dim3 block(SIZE, SIZE); // dim3 grid(n / SIZE, m / SIZE);
int idx_x = blockIdx.x * blockDim.x + threadIdx.x; int idx_y = blockIdx.y * blockDim.y + threadIdx.y;
float sum = 0.f; if (idx_x < n && idx_y < m) { for (int kk = 0; kk < k; ++kk) { sum += A[idx_y * k + kk] * B[kk * n + idx_x]; } C[idx_y * n + idx_x] = sum; } }
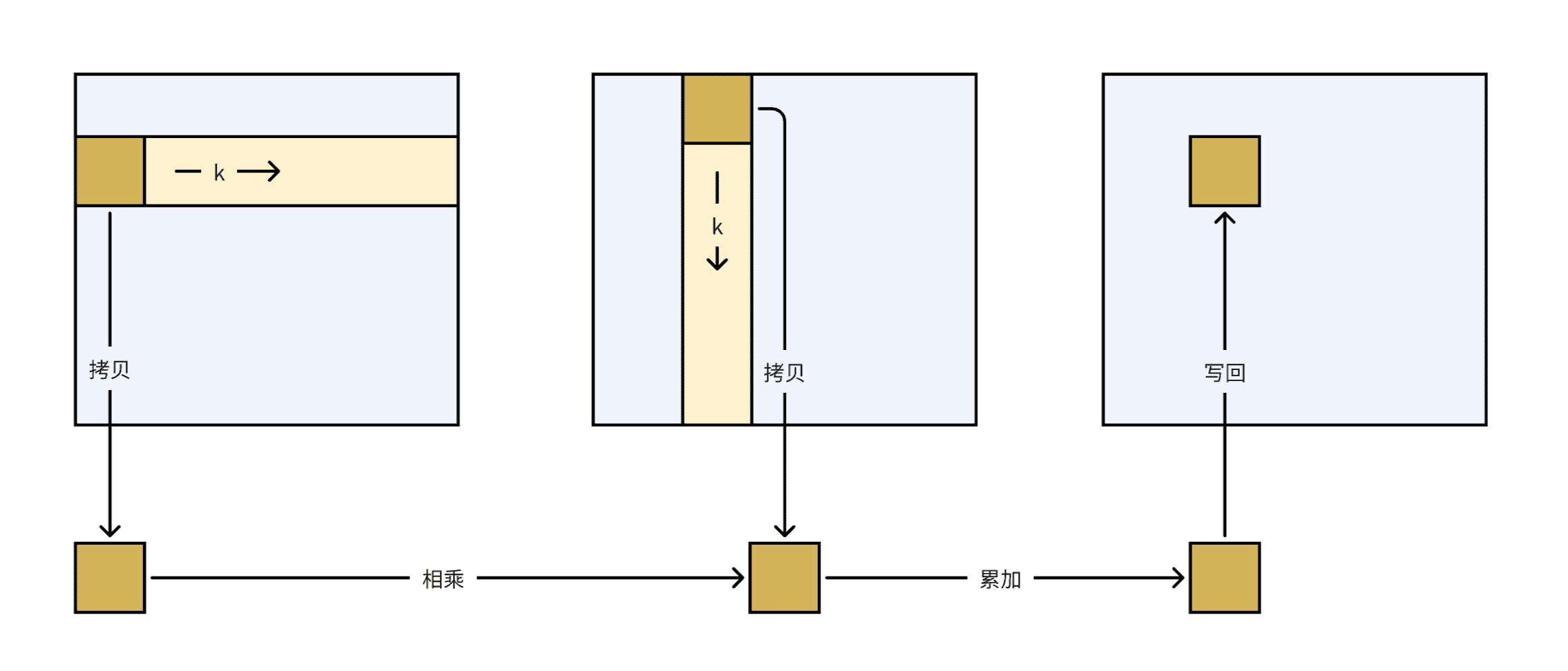
使用 shared memory
将每个 block 需要计算的数据先存放到 shared memory 中,减少对 global memory 的访存次数。
在这段代码中,每个 SIZE x SIZE 的 block 负责计算 C 中 SIZE x SIZE 的块,在外层循环的每次迭代中,首先将 A 和 B 中对应的块拷贝到共享内存,然后基于共享内存中的数据进行矩阵乘法,然后进行下一次迭代并将每次迭代的结果累加,最终得到 C 中对应的一块。在每次循环中,共享内存都会被更新。
int idx_x = blockIdx.x * blockDim.x + threadIdx.x; int idx_y = blockIdx.y * blockDim.y + threadIdx.y;
float sum = 0.0; for (int bk = 0; bk < k; bk += SIZE) { s_a[threadIdx.y][threadIdx.x] = A[idx_y * k + (bk + threadIdx.x)]; s_b[threadIdx.y][threadIdx.x] = B[(bk + threadIdx.y) * n + idx_x]; __syncthreads();
for (int i = 0; i < SIZE; ++i) { sum += s_a[threadIdx.y][i] * s_b[i][threadIdx.x]; } __syncthreads(); }
if (idx_x < n && idx_y < m) { C[idx_y * n + idx_x] = sum; } }
__global__ voidmatrixMultiplyKernel(float *A, float *B, float *C, int m, int n, int k){ // dim3 block(THREAD_X_PER_BLOCK, THREAD_Y_PER_BLOCK); // dim3 grid(n / BLOCK_SIZE_N, m / BLOCK_SIZE_M);
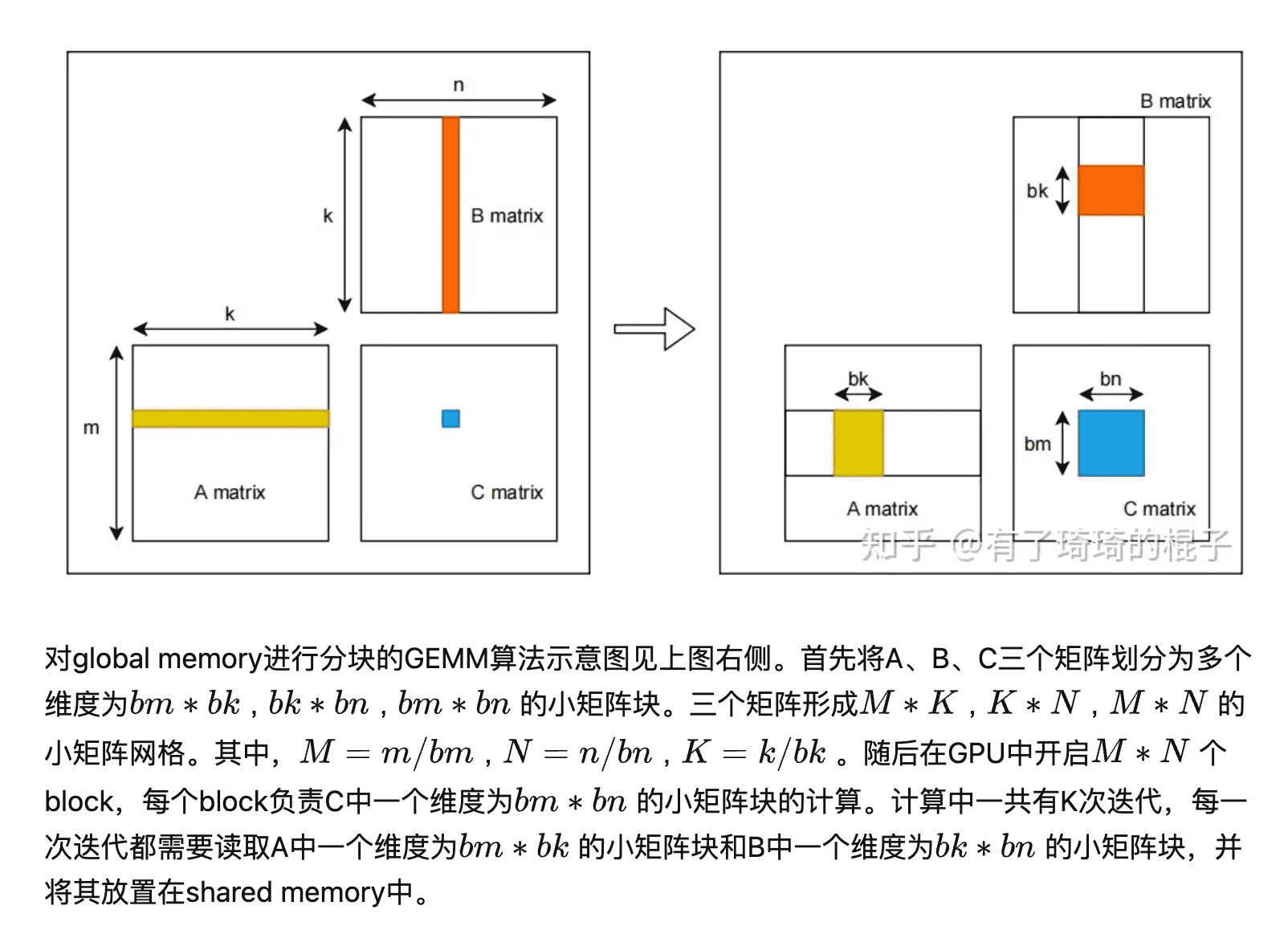
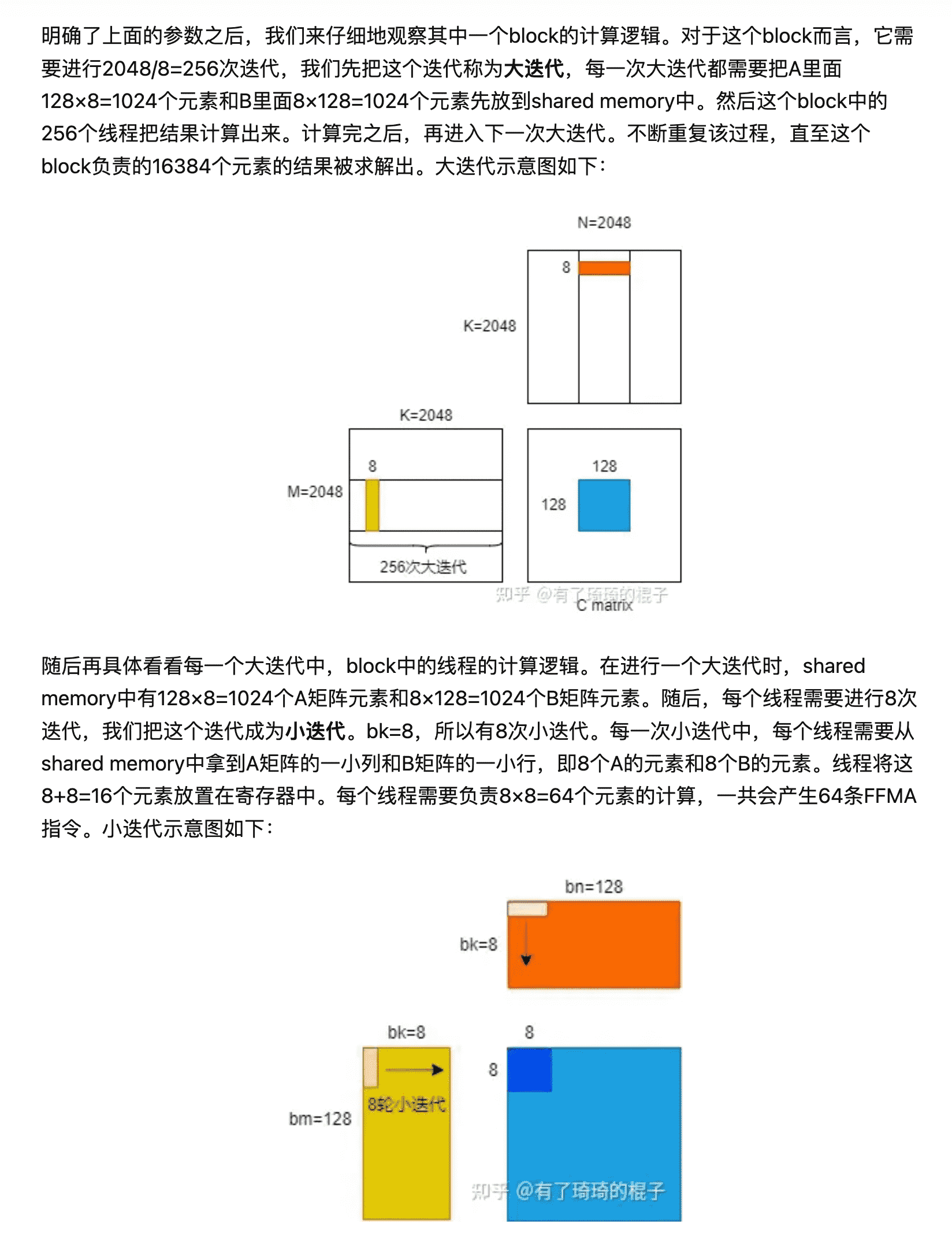
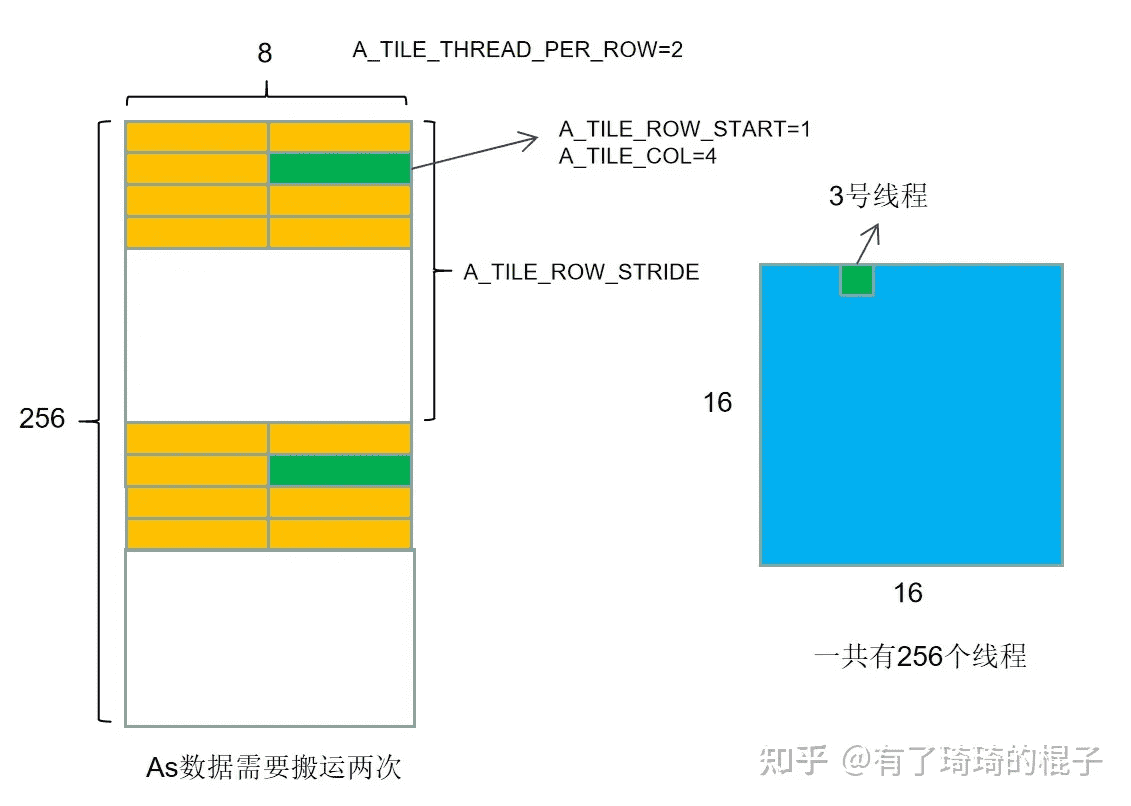
for (int bk = 0; bk < k; bk += BLOCK_SIZE_K) { // load A from global memory to shared memory #pragma unroll for (int i = 0; i < BLOCK_SIZE_M; i += A_TILE_ROW_STRIDE) { constint row = BLOCK_SIZE_M * blockIdx.y + i + A_TILE_ROW; constint col = bk + A_TILE_COL; if (blockIdx.x == gridDim.x - 1 || blockIdx.y == gridDim.y - 1) { s_a[i + A_TILE_ROW][A_TILE_COL] = row < m && col < k ? A[row * k + col] : 0; } else { s_a[i + A_TILE_ROW][A_TILE_COL] = A[row * k + col]; } }
// load B from global memory to shared memory #pragma unroll for (int i = 0; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { constint row = bk + i + B_TILE_ROW; constint col = BLOCK_SIZE_N * blockIdx.x + B_TILE_COL; if (blockIdx.x == gridDim.x - 1 || blockIdx.y == gridDim.y - 1) { s_b[i + B_TILE_ROW][B_TILE_COL] = row < k && col < n ? B[row * n + col] : 0; } else { s_b[i + B_TILE_ROW][B_TILE_COL] = B[row * n + col]; } }
__syncthreads();
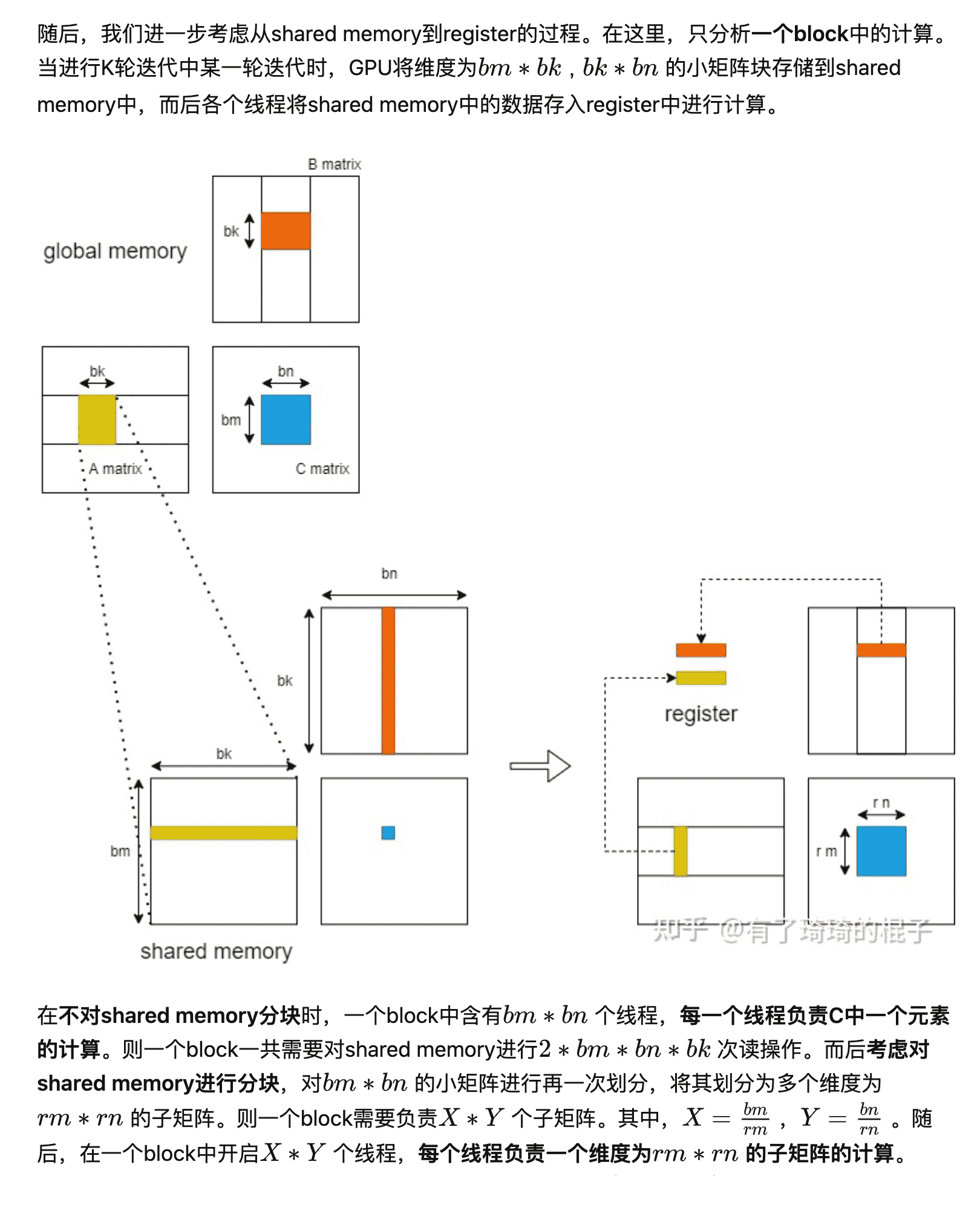
// 每个线程负责搬运的数据和接下来要计算的数据没有必然联系
// calculate C #pragma unroll for (int kk = 0; kk < BLOCK_SIZE_K; ++kk) { #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ++ty) { #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; ++tx) { r_c[ty][tx] += s_a[THREAD_SIZE_Y * threadIdx.y + ty][kk] * s_b[kk][THREAD_SIZE_X * threadIdx.x + tx]; } } }
__syncthreads(); }
// store back to C #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ++ty) { #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; ++tx) { constint row = BLOCK_SIZE_M * blockIdx.y + THREAD_SIZE_Y * threadIdx.y + ty; constint col = BLOCK_SIZE_N * blockIdx.x + THREAD_SIZE_X * threadIdx.x + tx; if (blockIdx.x == gridDim.x - 1 || blockIdx.y == gridDim.y - 1) { if (row < m && col < n) { C[row * n + col] += r_c[ty][tx]; } } else { C[row * n + col] += r_c[ty][tx]; } } } }
__global__ voidmatrixMultiplyKernel(float *A, float *B, float *C, int m, int n, int k){ // dim3 block(THREAD_X_PER_BLOCK, THREAD_Y_PER_BLOCK); // dim3 grid(n / BLOCK_SIZE_N, m / BLOCK_SIZE_M);
for (int bk = 0; bk < k; bk += BLOCK_SIZE_K) { // load A from global memory to shared memory #pragma unroll for (int i = 0; i < BLOCK_SIZE_M; i += A_TILE_ROW_STRIDE) { constint row = BLOCK_SIZE_M * blockIdx.y + i + A_TILE_ROW_START; constint col = bk + A_TILE_COL; FETCH_FLOAT4(s_a[i + A_TILE_ROW_START][A_TILE_COL]) = FETCH_FLOAT4(A[row * k + col]); }
// load B from global memory to shared memory #pragma unroll for (int i = 0; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { constint row = bk + i + B_TILE_ROW_START; constint col = BLOCK_SIZE_N * blockIdx.x + B_TILE_COL; FETCH_FLOAT4(s_b[i + B_TILE_ROW_START][B_TILE_COL]) = FETCH_FLOAT4(B[row * n + col]); }
__syncthreads();
// 每个线程负责搬运的数据和接下来要计算的数据没有必然联系
// calculate C #pragma unroll for (int kk = 0; kk < BLOCK_SIZE_K; ++kk) { // load A from shared memory to register #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ++ty) { frag_a[ty] = s_a[THREAD_SIZE_Y * threadIdx.y + ty][kk]; }
// load B from shared memory to register #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; tx += 4) { FETCH_FLOAT4(frag_b[tx]) = FETCH_FLOAT4(s_b[kk][THREAD_SIZE_X * threadIdx.x + tx]); }
#pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ++ty) { #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; ++tx) { r_c[ty][tx] += frag_a[ty] * frag_b[tx]; } } } }
// store back to C #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ++ty) { #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; tx += 4) { constint row = BLOCK_SIZE_M * blockIdx.y + THREAD_SIZE_Y * threadIdx.y + ty; constint col = BLOCK_SIZE_N * blockIdx.x + THREAD_SIZE_X * threadIdx.x + tx; FETCH_FLOAT4(C[row * n + col]) = FETCH_FLOAT4(r_c[ty][tx]); } } }
__global__ voidmatrixMultiplyKernel(float * A, float * B, float * C, int m, int n, int k){ // dim3 block(THREAD_X_PER_BLOCK, THREAD_Y_PER_BLOCK); // dim3 grid(n / BLOCK_SIZE_N, m / BLOCK_SIZE_M);
// preload A from global memory to shared memory #pragma unroll for (int i = 0; i < BLOCK_SIZE_M; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; constint row = BLOCK_SIZE_M * blockIdx.y + i + A_TILE_ROW_START; constint col = A_TILE_COL; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[row * k + col]); s_a[0][A_TILE_COL + 0][i + A_TILE_ROW_START] = ldg_a_reg[ldg_index + 0]; s_a[0][A_TILE_COL + 1][i + A_TILE_ROW_START] = ldg_a_reg[ldg_index + 1]; s_a[0][A_TILE_COL + 2][i + A_TILE_ROW_START] = ldg_a_reg[ldg_index + 2]; s_a[0][A_TILE_COL + 3][i + A_TILE_ROW_START] = ldg_a_reg[ldg_index + 3]; }
// preload B from global memory to shared memory #pragma unroll for (int i = 0; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { constint row = i + B_TILE_ROW_START; constint col = BLOCK_SIZE_N * blockIdx.x + B_TILE_COL; FETCH_FLOAT4(s_b[0][i + B_TILE_ROW_START][B_TILE_COL]) = FETCH_FLOAT4(B[row * n + col]); }
__syncthreads();
// preload A from shared memory to register #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ty += 4) { FETCH_FLOAT4(frag_a[0][ty]) = FETCH_FLOAT4(s_a[0][0][THREAD_SIZE_Y * threadIdx.y + ty]); }
// preload B from shared memory to register #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; tx += 4) { FETCH_FLOAT4(frag_b[0][tx]) = FETCH_FLOAT4(s_b[0][0][THREAD_SIZE_X * threadIdx.x + tx]); }
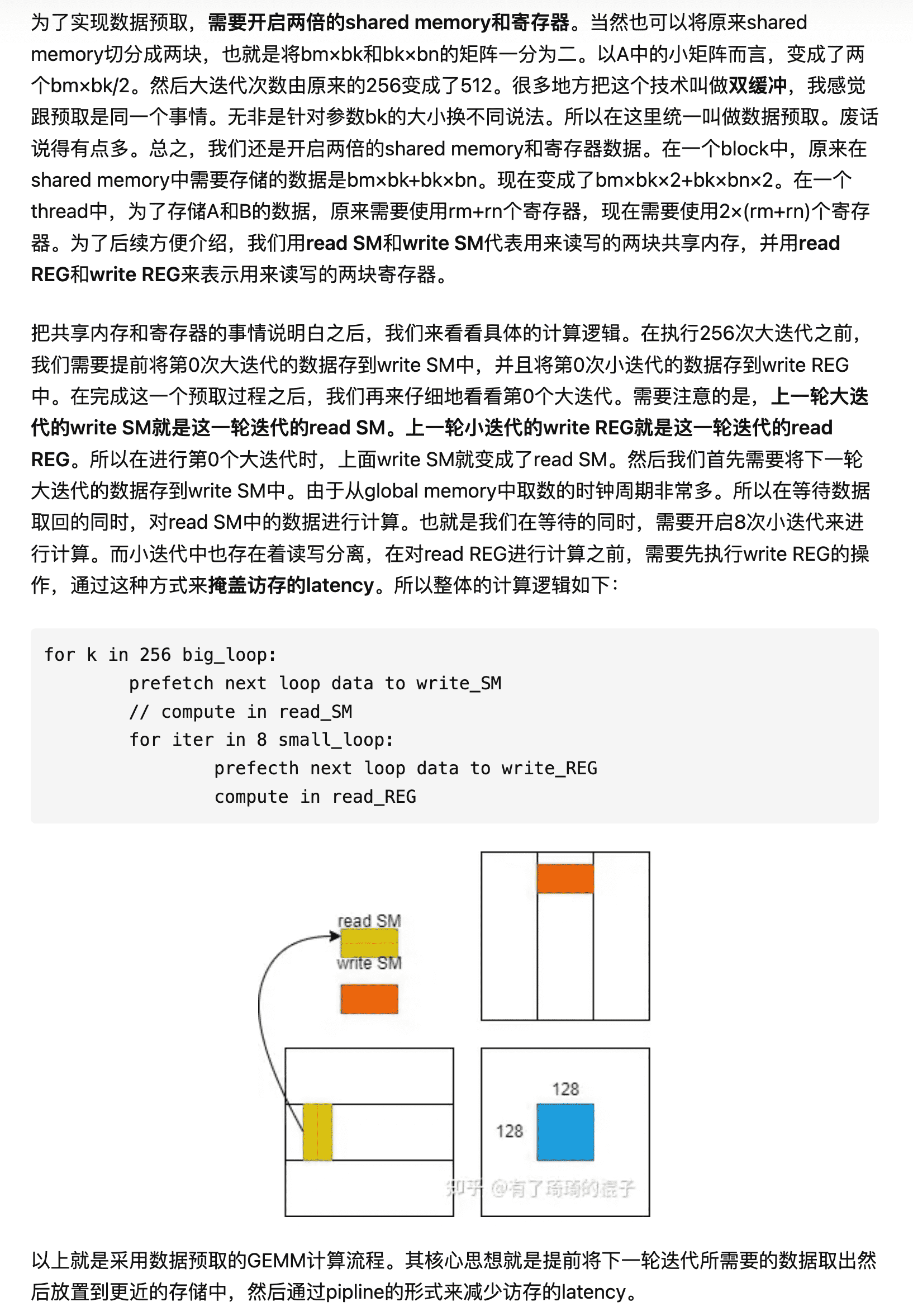
int write_stage_idx = 1; int bk = 0; do { bk += BLOCK_SIZE_K;
if (bk < k) { // preload A from global memory to register #pragma unroll for (int i = 0; i < BLOCK_SIZE_M; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; constint row = BLOCK_SIZE_M * blockIdx.y + i + A_TILE_ROW_START; constint col = bk + A_TILE_COL; FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[row * k + col]); }
// preload B from global memory to register #pragma unroll for (int i = 0; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / B_TILE_ROW_STRIDE * 4; constint row = bk + i + B_TILE_ROW_START; constint col = BLOCK_SIZE_N * blockIdx.x + B_TILE_COL; FETCH_FLOAT4(ldg_b_reg[ldg_index]) = FETCH_FLOAT4(B[row * n + col]); } }
// 每个线程负责搬运的数据和接下来要计算的数据没有必然联系
int load_stage_idx = write_stage_idx ^ 1;
// calculate C #pragma unroll for (int kk = 0; kk < BLOCK_SIZE_K - 1; ++kk) { // preload A from shared memory to register #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ty += 4) { FETCH_FLOAT4(frag_a[(kk + 1) % 2][ty]) = FETCH_FLOAT4(s_a[load_stage_idx][kk + 1][THREAD_SIZE_Y * threadIdx.y + ty]); }
// preload B from shared memory to register #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; tx += 4) { FETCH_FLOAT4(frag_b[(kk + 1) % 2][tx]) = FETCH_FLOAT4(s_b[load_stage_idx][kk + 1][THREAD_SIZE_X * threadIdx.x + tx]); }
// calculate C (this tile) #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ++ty) { #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; ++tx) { r_c[ty][tx] += frag_a[kk % 2][ty] * frag_b[kk % 2][tx]; } } }
if (bk < k) { // preload A from register to shared memory #pragma unroll for (int i = 0; i < BLOCK_SIZE_M; i += A_TILE_ROW_STRIDE) { int ldg_index = i / A_TILE_ROW_STRIDE * 4; s_a[write_stage_idx][A_TILE_COL + 0][i + A_TILE_ROW_START] = ldg_a_reg[ldg_index + 0]; s_a[write_stage_idx][A_TILE_COL + 1][i + A_TILE_ROW_START] = ldg_a_reg[ldg_index + 1]; s_a[write_stage_idx][A_TILE_COL + 2][i + A_TILE_ROW_START] = ldg_a_reg[ldg_index + 2]; s_a[write_stage_idx][A_TILE_COL + 3][i + A_TILE_ROW_START] = ldg_a_reg[ldg_index + 3]; }
// preload B from register to shared memory #pragma unroll for (int i = 0; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) { int ldg_index = i / B_TILE_ROW_STRIDE * 4; FETCH_FLOAT4(s_b[write_stage_idx][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(ldg_b_reg[ldg_index]); }
__syncthreads(); write_stage_idx ^= 1; }
// preload A from shared memory to register #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ty += 4) { FETCH_FLOAT4(frag_a[0][ty]) = FETCH_FLOAT4(s_a[load_stage_idx ^ 1][0][THREAD_SIZE_Y * threadIdx.y + ty]); }
// preload B from shared memory to register #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; tx += 4) { FETCH_FLOAT4(frag_b[0][tx]) = FETCH_FLOAT4(s_b[load_stage_idx ^ 1][0][THREAD_SIZE_X * threadIdx.x + tx]); }
// compute last tile matmul THREAD_SIZE_X * THREAD_SIZE_Y #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ++ty) { #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; ++tx) { r_c[ty][tx] += frag_a[1][ty] * frag_b[1][tx]; } }
} while(bk < k);
// store back to C #pragma unroll for (int ty = 0; ty < THREAD_SIZE_Y; ++ty) { #pragma unroll for (int tx = 0; tx < THREAD_SIZE_X; tx += 4) { constint row = BLOCK_SIZE_M * blockIdx.y + THREAD_SIZE_Y * threadIdx.y + ty; constint col = BLOCK_SIZE_N * blockIdx.x + THREAD_SIZE_X * threadIdx.x + tx; FETCH_FLOAT4(C[row * n + col]) = FETCH_FLOAT4(r_c[ty][tx]); } } }