OpenCL 基本概念 | OpenCL
OpenCL 是一个异构计算开放标准。支持 OpenCL 的各厂商设备的硬件实现可能不一样,但是都可以通过 OpenCL 来调度计算单元完成计算任务。
平台模型
平台模型描述了协同执行的单个处理器(host)以及一个或者多个能执行 OpenCL 代码的处理器(device)。OpenCL device 内部由多个计算单元(CU)组成,每一个 CU 可以继续划分为处理单元(PU/PE)。
执行模型
执行模型描述了在 host 上如何配置 OpenCL 环境以及如何在 device 上执行 kernel。这包括在 host 建立上下文,提供 host 和 device 之间的交互机制,定义一个并发模型供在设备上执行 kernel 所用。
上下文
host 主要通过上下文(Context)管理 OpenCL device,上下文指的是所管理硬件和软件资源,包括:
- device:OpenCL 程序调用的计算设备
- kernel:在 device 上执行的并行程序
- 程序对象:kernel 的源代码(*.cl)和可执行文件
- 内存对象:device 执行 OpenCL 程序所需要的变量
命令队列
host 主要通过命令对 device 进行进行控制。每一个 device 都会有一个命令队列,命令队列只能管理一个 device。通过命令队列,就实现了 host 和 device 的异步控制与执行。命令队列和 CUDA 中的 stream 对等。
队列中的命令主要有三种:
- 启动命令:OpenCL 设备开始执行内核程序
- 内存命令:在 host 内存和 device 内存之间移动数据,或者在两者之间进行内存映射
- 同步命令:约束命令在计算设备上的执行
- 有序命令:命令按照在命令队列的顺序进行发射和执行,上一条命令执行完后才能发射下一条命令
- 乱序执行:命令按照在命令队列中的顺序进行发射,但不保证 device 是按照这个顺序进行执行的
host 可以为一个 device 创建多个命令队列(一个计算设备可以有多个命令队列)。这些命令队列没有关联,这也就意味着一个 device 可以并发执行多个任务。
既然是异步执行方式,就需要同步操作,OpenCL 有三种同步方式:
- 同一个工作组的工作项间进行数据同步
- 同一个命令队列中的命令进行同步
- 同一个上下文的命令队列进行同步
事件
任何操作被作为一个命令入队到一个命令队列中,即任何以 clEnqueue 字样开头的 API 调用,都会产生一个事件。事件在 OpenCL 中有两大作用:表示依赖和提供程序剖析机制。每次 clEnqueue 调用都将阻塞直到等待列表中的所有事件完成。
计算单元描述
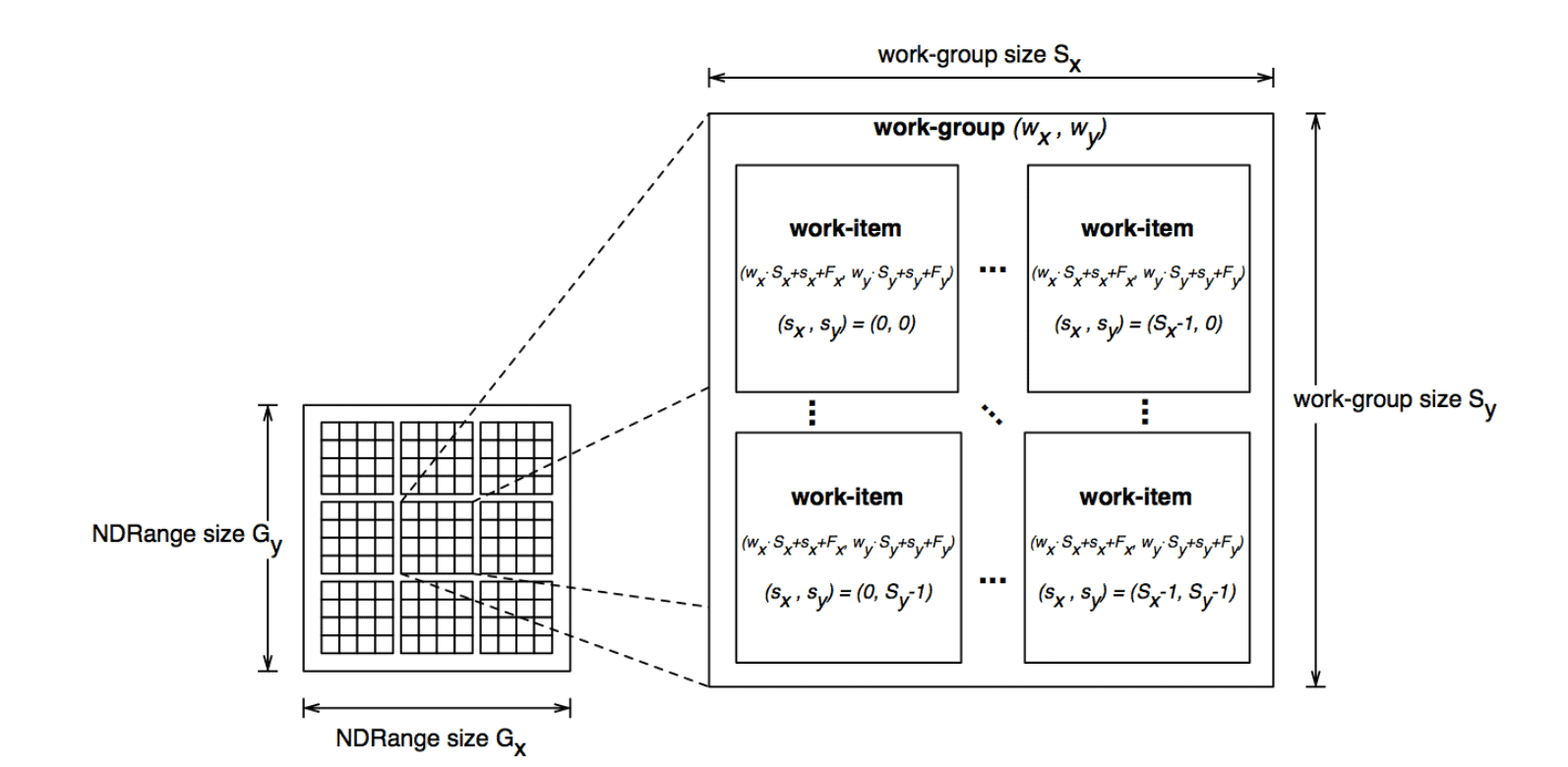
- 工作项(work item):最基础的计算单元,多个工作项执行同样的核函数,每个工作项都有一个唯一固定的 ID(和 CUDA 中的 thread 对等)
- 工作组(work group):多个工作项组成一个工作组,同一个工作组中的工作项之间可以通信(和 CUDA 中的 block 对等)
- ND-Range:定义了工作组的组织形式(和 CUDA 中的 grid 对等)
- PE/PU:和 CUDA 中的 SP 对等
- CU:和 CUDA 中的 SM 对等
- wavefront(AMD GPU 中的概念):和 CUDA 中的 warp 对等
内存模型
.png)
内存模型描述了被 kernel 所用的抽象内存层次,无需考虑实际的硬件实现。OpenCL 将设备中的存储器抽象成四层结构的存储模型:
- 全局变量内存:所有工作项可读写
- 全局常量内存:所有工作项可读不可写
- 本地内存:同一个工作组中的工作项可以进行读写,对其他工作组不可见
- 私有内存:只对单个工作项可见
在程序运行期间,需要 host 和 device 进行数据交换,有两种方式:
- 数据拷贝:将需要的数据拷贝到全局变量内存,计算完成后再拷贝出去
- 内存映射:将需要计算的地址传进去
编程模型
编程模型描述了如何将并发模型映射到物理硬件上。计算的时候可以按照两种类型模型来进行计算:
- 数据并行:将需要计算的数据进行等分,分配给不同的 device 同时进行计算
- 任务并行:如果计算数据量不大,但每一步骤前后依赖,就可以把任务分成好几个阶段,用多个 device 同时计算不同阶段,即流水线模式
参考
《OpenCL 异构计算》
OpenCL 基本概念 | OpenCL