# Token types # # EOF (end-of-file) token is used to indicate that # there is no more input left for lexical analysis INTEGER, PLUS, MINUS, MUL, DIV, LPAREN, RPAREN, EOF = ( 'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', '(', ')', 'EOF' )
classToken(object): def__init__(self, type, value): self.type = type self.value = value
def__str__(self): """String representation of the class instance. Examples: Token(INTEGER, 3) Token(PLUS, '+') Token(MUL, '*') """ return'Token({type}, {value})'.format( type=self.type, value=repr(self.value) )
def__repr__(self): return self.__str__()
classLexer(object): def__init__(self, text): # client string input, e.g. "4 + 2 * 3 - 6 / 2" self.text = text # self.pos is an index into self.text self.pos = 0 self.current_char = self.text[self.pos]
defadvance(self): """Advance the `pos` pointer and set the `current_char` variable.""" self.pos += 1 if self.pos > len(self.text) - 1: self.current_char = None# Indicates end of input else: self.current_char = self.text[self.pos]
defskip_whitespace(self): while self.current_char isnotNoneand self.current_char.isspace(): self.advance()
definteger(self): """Return a (multidigit) integer consumed from the input.""" result = '' while self.current_char isnotNoneand self.current_char.isdigit(): result += self.current_char self.advance() returnint(result)
defget_next_token(self): """Lexical analyzer (also known as scanner or tokenizer) This method is responsible for breaking a sentence apart into tokens. One token at a time. """ while self.current_char isnotNone:
if self.current_char.isspace(): self.skip_whitespace() continue
if self.current_char.isdigit(): return Token(INTEGER, self.integer())
if self.current_char == '+': self.advance() return Token(PLUS, '+')
if self.current_char == '-': self.advance() return Token(MINUS, '-')
if self.current_char == '*': self.advance() return Token(MUL, '*')
if self.current_char == '/': self.advance() return Token(DIV, '/')
if self.current_char == '(': self.advance() return Token(LPAREN, '(')
if self.current_char == ')': self.advance() return Token(RPAREN, ')')
self.error()
return Token(EOF, None)
classInterpreter(object): def__init__(self, lexer): self.lexer = lexer # set current token to the first token taken from the input self.current_token = self.lexer.get_next_token()
deferror(self): raise Exception('Invalid syntax')
defeat(self, token_type): # compare the current token type with the passed token # type and if they match then "eat" the current token # and assign the next token to the self.current_token, # otherwise raise an exception. if self.current_token.type == token_type: self.current_token = self.lexer.get_next_token() else: self.error()
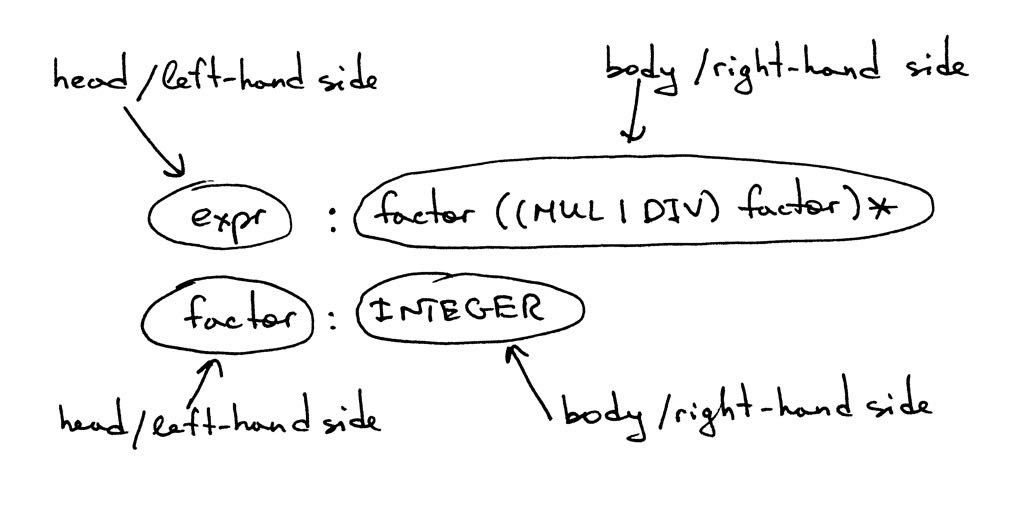
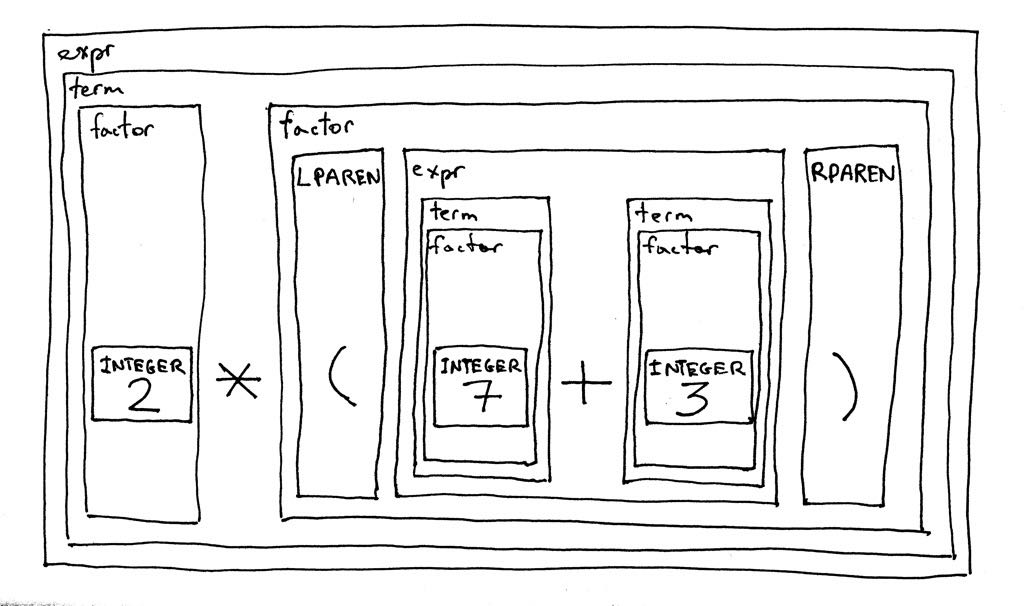
deffactor(self): """factor : INTEGER | LPAREN expr RPAREN""" token = self.current_token if token.type == INTEGER: self.eat(INTEGER) return token.value elif token.type == LPAREN: self.eat(LPAREN) result = self.expr() self.eat(RPAREN) return result
while self.current_token.typein (MUL, DIV): token = self.current_token if token.type == MUL: self.eat(MUL) result = result * self.factor() elif token.type == DIV: self.eat(DIV) result = result // self.factor()
while self.current_token.typein (PLUS, MINUS): token = self.current_token if token.type == PLUS: self.eat(PLUS) result = result + self.term() elif token.type == MINUS: self.eat(MINUS) result = result - self.term()